Sügavõpe (Deep Learning) — definitsioon, toimimispõhimõte ja rakendused
Sügavõpe: definitsioon, toimimispõhimõte ja praktilised rakendused — kõnetuvastus, pildianalüüs, käekiri ja rohkem. Mõista, kuidas mitmekihilised närvivõrgud töötavad.
Sügavõpe (mida nimetatakse ka sügavaks struktureeritud õppeks või hierarhiliseks õppeks) on üks masinõppe liik, mida kasutatakse peamiselt teatud tüüpi närvivõrkude puhul. Nagu muude masinõppe meetodite puhul, võivad õppesessioonid olla järelevalveta, pooljuhitud või juhitud. Sageli on mudeli struktuur korraldatud nii, et sisendkihi ja väljundkihi vahel on mitu vahekihti ehk varjatud kihti; just nende mitmekihilisus võimaldab õppida keerukaid mustreid ja abstraktsioone.
Teatud ülesandeid, nagu näiteks kõne, piltide või käekirja äratundmine ja mõistmine, on inimesel lihtne täita. Arvutile on need ülesanded aga algselt väga keerulised, sest need nõuavad järjestikust andmete töötlemist ja kõrgetasemelise tähenduse eraldamist nii mürast kui variatsioonidest. Mitmekihilise neurovõrgu puhul (millel on rohkem kui kaks kihti) muutub töödeldav teave iga lisanduva kihiga abstraktsemaks: madalamad kihid õpivad lihtsamaid tunnuseid (nt servad piltidel), kõrgemad kihid kombineerivad neid keerulisemateks konstruktsioonideks (nt objektid või semantilised mõisted).
Süvaõppe mudelid on inspireeritud bioloogiliste närvisüsteemide infotöötlus- ja kommunikatsioonimudelitest; need erinevad bioloogiliste ajude (eriti inimese aju) struktuurilistest ja funktsionaalsetest omadustest mitmel viisil, mistõttu ei saa süvaõppe mudeleid otseselt pidada bioloogiliseks ekvivalendiks ning neid ei saa täielikult selgitada üksnes neuroteaduslike tõenditega. Samas on bioloogiline inspiratsioon aidanud leida arhitektuure ja õppimisvõtteid, mis toimivad keerukate andmete korral hea tulemuslikkusega.
Pildigalerii
3 Pildid
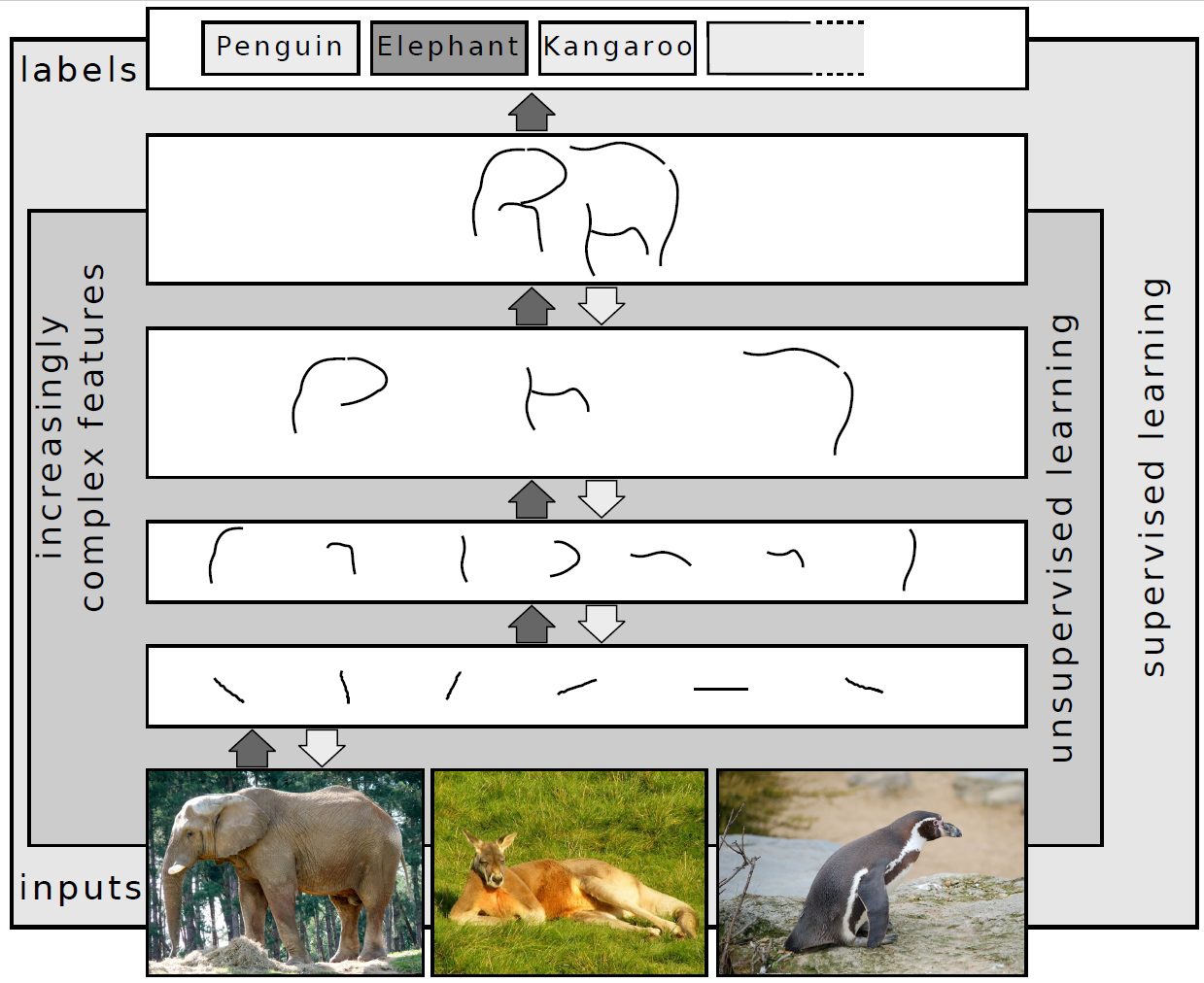
Kuidas sügavõpe töötab
Sügavõpe põhineb suurte närvivõrkude treenimisel näidetest (andmetest). Peamised komponendid on:
- Andmed: sildistatud või sildistamata näited, mida kasutatakse õppimiseks.
- Mudel: närvivõrgu arhitektuur koos kihtide, neuronite ja aktiivsusega funktsioonidega.
- Kahjufunktsioon: mõõdik, mis ütleb, kui kaugel mudeli ennustus on sihtväärtusest.
- Optimeerija: algoritm (nt gradientlangevuse variandid), mis värskendab kaalusid kahju vähendamiseks, kasutades tagasi-sügamist ehk backpropagationit.
- Regulaarimine: meetodid (nt dropout, L2 regulaarimine, andmete augmentatsioon), et vältida mudeli üleõppimist.
Peamised arhitektuurid
- Tihedad (feedforward) närvivõrgud: lihtsam vorm, kus info liigub ühest kihist järgmisesse (kasulik üldiste regressiooni- ja klassifikatsioonitööde puhul).
- Konvolutsioonivõrgud (CNN): optimeeritud piltide ja ruumiliste andmete töötluseks—kasutavad konvolutsioonilisi filtreid tunnuste automaatseks õppimiseks.
- Sekventsiaalvõrgud (RNN, LSTM, GRU): loovad sõltuvusi järjestikusest andmest (nt tekst, kõne, ajaseeria), LSTM ja GRU aitavad lahendada pikaajalisi sõltuvusi.
- Transformerid: tänapäeval väga edukad mudelid loomuliku keele töötlemisel ja mujal; põhinevad tähelepanu (attention) mehhanismil, mis suudab paralleelselt töödelda kogu sisendit ja tabada kaugemate elementide suhteid.
- Generatiivsed mudelid (GAN, VAE): sobivad uute näidete genereerimiseks, andmete täiustamiseks ja loominguliste ülesannete lahendamiseks.
Koolitus ja optimeerimine
Sügavõppe mudelite treenimine nõuab tavaliselt suurt hulka andmeid ja arvutusressursse (GPU/TPU). Treenimise üldine töövoog sisaldab andmete ettevalmistust ja normaliseerimist, mudeli initsialiseerimist, valitud kaotuse optimeerimist ja mudeli hindamist eraldi valideerimiskogumil. Olulised teemad on:
- Backpropagation: gradientide arvutamine ja kaaluvärskendused.
- Õppimismäär ja selle graafikud: liiga suur õppimismäär võib põhjustada kõikumist, liiga väike aeglustab konvergentsi; sageli kasutatakse ajapõhiseid schemreid või adaptatiivseid optimeerijaid (Adam, RMSprop).
- Andmete jagamine: treening, valideerimine ja test—hindamiseks peab olema eraldi andmepõhi, mida mudel treenimisel ei näe.
- Hyperparameetrite häälestus: kihiarvud, neuronite arv, partiisuurus, dropout jne. Tihti kasutatakse ridade/ruumiotsingut või automaatseid tööriistu (hyperopt, Optuna).
Rakendused
Sügavõpe on laialdaselt rakendatav mitmes valdkonnas:
- Arvutinägemine: objektituvastus, pildisegmentatsioon, meditsiiniliste piltide analüüs.
- Kõnetuvastus ja kõnetöötlus: häältuvastus, kõnesüntees, helipõhine autentimine.
- Looduskeele töötlemine (NLP): masintõlge, teksti süntees, tekstikokkuvõtted ja küsimustele vastamine (transformerid ja pretrainitud mudelid nagu BERT, GPT-tüübid).
- Autonoomne juhtimine ja robootika: teekonna planeerimine, objektide tuvastus ja reaalajas otsused.
- Soovitussüsteemid ja analüütika: kasutajate käitumise modelleerimine ja personaalsed soovitused.
- Meditsiin ja biotehnoloogia: haiguse diagnoos, ravimite avastamine ja geneetiliste andmete analüüs.
Eelised ja piirangud
Sügavõppe eelised on võime automaatselt tuvastada keerulisi tunnuseid ja töötada suure hulga andmetega, mis võimaldab saavutada sageli tipptasemel tulemusi. Kuid on ka olulisi piiranguid:
- Andmepõhisus: toimivus sõltub tugevalt treeningandmete hulgast ja kvaliteedist.
- Arvutuslikud kulud: treenimiseks ja häälestamiseks on vaja palju ressursse (GPU/TPU ja energiat).
- Selgitatavuse puudumine: sügavad mudelid on sageli “must kast”, mis teeb keeruliseks otsuste põhjendamise.
- Kalduvus eelarvamustele: kui treeningandmed sisaldavad kallutatust, väljendab mudel seda ka oma otsustes.
Praktilised soovitused
- Kogu ja puhasta andmeid hoolikalt: kvaliteetseid andmeid on sageli olulisem kui veelgi suurema mudeli kasutamine.
- Kasutage andmete augmentatsiooni ja regulaarimismeetodeid üleõppimise vähendamiseks.
- Alustage lihtsamast arhitektuurist ja kasvage vajadusel keerukamaks; üleliigne keerukus suurendab vigade ja treeningkulude riski.
- Kasutage olemasolevaid eelõpetatud mudeleid ja transfer learningi, et säästa andmeid ja arvutusressursse—see on eriti kasulik väiksemate andmekogude puhul.
- Jälgige tublisti valideerimis- ja testmõõdikuid (nt täpsus, F1, AUC), et hinnata mudeli üldistuvust.
Sügavõpe on kiirelt arenev valdkond, kus nii teoreetilised edusammud (näiteks uued arhitektuurid ja optimeerijad) kui ka paremad riistvararessursid avavad pidevalt uusi rakendusvõimalusi. Kuigi meetoditel on piirangud, pakuvad need tänapäeval töövahendeid, mis lahendavad ülesandeid, mis varem tundusid automaatseks lahendamiseks liiga keerulised.

Küsimused ja vastused
K: Mis on süvaõpe?
V: Sügavõpe on masinõppe liik, mis kasutab teabe töötlemiseks närvivõrke ja on sageli korraldatud vähemalt ühe vahepealse (varjatud) kihiga sisend- ja väljundkihtide vahel.
K: Milliseid erinevaid õppesessioone kasutatakse süvaõppes?
V: Sügavõpe võib olla korraldatud järelevalveta, pooljuhitud ja juhitud õppesessioonideks.
K: Millised on ülesanded, mida on inimesele lihtne, kuid arvutile raske täita?
V: Sellised ülesanded nagu kõne, pildi või käekirja äratundmine ja mõistmine on inimestele lihtsad, kuid arvutitele rasked.
K: Mis juhtub teabega, kui seda töödeldakse mitmekihilises närvivõrgus?
V: Mitmekihilises neurovõrgus muutub töödeldud teave iga lisanduva kihiga abstraktsemaks.
K: Millest on inspireeritud süvaõppe mudelid?
V: Sügava õppimise mudelid on inspireeritud bioloogiliste närvisüsteemide teabetöötlus- ja kommunikatsioonimustritest.
K: Mille poolest erinevad süvaõppe mudelid bioloogiliste ajude omadustest?
V: Sügava õppimise mudelid erinevad bioloogiliste ajude, eriti inimese aju struktuursetest ja funktsionaalsetest omadustest mitmel viisil, mis muudab need neuroteaduslike tõenditega kokkusobimatuks.
K: Mis on teine termin sügava õppimise kohta?
V: Sügavat õppimist nimetatakse ka sügavaks struktureeritud õppimiseks või hierarhiliseks õppimiseks.
Seotud artiklid
Autor
AlegsaOnline.com Sügavõpe (Deep Learning) — definitsioon, toimimispõhimõte ja rakendused Leandro Alegsa
URL: https://et.alegsaonline.com/art/26216
Allikad
- ncbi.nlm.nih.gov : "Toward an Integration of Deep Learning and Neuroscience"
- doi.org : 10.3389/fncom.2016.00094
- pubmed.ncbi.nlm.nih.gov : 27683554
- ui.adsabs.harvard.edu : 1996Natur.381..607O
- doi.org : 10.1038/381607a0
- pubmed.ncbi.nlm.nih.gov : 8637596