Zipfi seadus — definitsioon, matemaatika ja näited keeles ja ühiskonnas
Zipfi seadus — definitsioon, matemaatika ja elulised näited keeles ja ühiskonnas, kuidas sõnade, linnade ja ettevõtete sagedused järgivad 1/n reeglit
Zipfi seadus on matemaatilise statistika abil sõnastatud empiiriline seadus, mis on nime saanud selle esmakordselt välja pakkunud keeleteadlase George Kingsley Zipfi järgi.
Zipfi seadus ütleb, et suure kasutatava sõnade valimi puhul on iga sõna sagedus pöördvõrdeline selle järjekohaga sagedustabelis. Seega on sõna number n sagedus võrdeline 1/n.
Praktiliselt tähendab see, et kõige sagedasem sõna esineb ligikaudu kaks korda sagedamini kui teine, kolm korda sagedamini kui kolmas jne. Näiteks ühes inglise keele sõnade valimis moodustab kõige sagedamini esinev sõna "the" peaaegu 7% kõigist sõnadest (69 971 sõna veidi üle 1 miljoni). Zipfi seaduse kohaselt moodustab teisel kohal olev sõna "of" veidi üle 3,5% sõnadest (36 411 esinemist), millele järgneb sõna "and" (28 852). Vaid umbes 135 sõna on vaja, et moodustada pool suure valimi sõnadest.
Pildigalerii
3 Pildid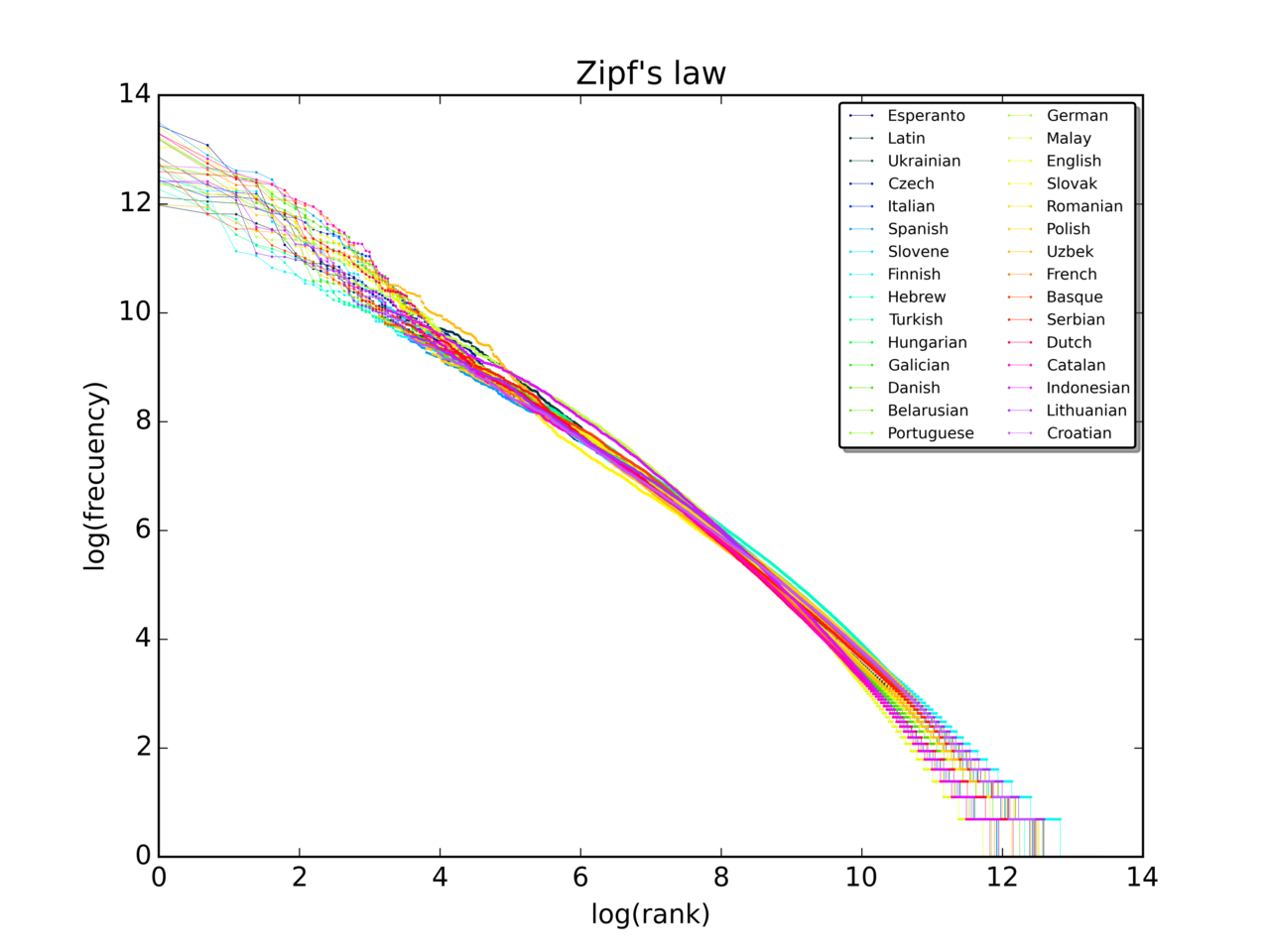


Matemaatiline kuju
Zipfi seadust saab kirjeldada täpsemalt võrdlusega:
f(r) ∝ 1 / r^s,
kus r on sõna järjekohakoht (rank), f(r) selle sagedus ja s on parameeter, mis keele puhul on sageli ligikaudu 1. Kui s = 1 ja arvestada lõpliku sõnavaru N, siis sagedused normaliseeritakse konstandiga C = 1 / H_N (H_N on N-nda harmooniline arv), ehk
f(r) = C / r.
Zipfi seadus on seega erijuht, kus langemise kiirus log-log graafikul on ligikaudu −1. Reaalses andmestikus võib s erineda järjekorrati, nii et täpsem mudel on Zipf–Mandelbrot kujul f(r) ∝ 1 / (r + q)^s, mis annab parema sobivuse tipu ja saba osas.
Põhjused ja teooriad
- Keelte sisemine dünaamika: mõned teooriad seovad Zipfi seaduse keele efektiivsuse ja kommunikatiivsete survetega: sagedased sõnad kipuvad olema lühikesed ja kergesti ligipääsetavad (Zipfi enda arutlused).
- Stohhastilised mudelid: Herbert A. Simon pakkus välja lihtsa kasvumudeli, kus uute üksuste (nt sõnade, firmade) tekkimine ja olemasolevate suuruste „eelistav kinnitamine“ (preferential attachment) viivad pikiastmelise (power-law) jaotuse tekkele.
- Mandelbroti laiendus: Zipfi seaduse kohandused (nt Zipf–Mandelbrot) parandasid sobivust eriti kõrgete ja madalate ordinaatide juures.
- Pseudo-juhuslikud mudelid: nn "monkey typing" eksperiment (juhuslik täheke ja tühikute kombineerimine) näitab, et osa zipfilikust käitumisest võib tuleneda kombinatoorsetest efektidest, kuid see ei selgita kõiki observatsioone reaalses keeles.
Rakendused ja näited ühiskonnas
Zipfi seadust ei leita üksnes keeles. Sarnane jõujoon ilmneb paljudes järjestatud jaotustes:
- linnade rahvaarvud (suure linnade sagedushierarhia), kus Felix Auerbach 1913. aastal märkas esimesi näiteid;
- ettevõtete suurusjärjestused ja tulujaotused;
- perekonnanimede sagedused (teatud riikides mõningad perekonnanimed esinevad väga sageli);
- veebilehtede külastatavus ja populaarsete sõnade/hashtagide esinemissagedused sotsiaalmeedias;
- mõnede loodusnähtuste ja tehniliste süsteemide jaotused, kus toimib „raske saba“ ehk power-law käitumine.
Mõned piirangud ja kriitika
- Zipfi seadus on empiiriline: see ei ole absoluutne reegel ja ei kehti täpselt kõigi korpuste või keelte puhul.
- Väikestes või valikuliselt koostatud korpustes võib jaotus olla tugevasti kõverdatud või moonutatud (nt tekstide žanrid, morfoloogiliselt rikkad keeled).
- Kui analüüsida ainult funktsionaalseid sõnu (artiklid, sidesõnad) vs. tähenduslikke leksikaalseid sõnu, näeb joonis eri käitumist tipus ja sabas.
- Teooriate vahel puudub täielik konsensus – on mitu võimalikku mehhanismi, mis annavad sarnase lõpptulemuse.
Kuidas Zipfi seadust kontrollida või visualiseerida
- Kogu suur ja mitmekesine tekstikorpus (miljon+ sõna) ning loendi sõnade esinemissagedustest.
- Sorteeri sõnad sageduse kahanevas järjekorras ja jaga igale sõnale järjekorranumber (rank).
- Joonista rank vs. frequency log-log skaalal — kui andmed on ligikaudu Zipfi tüüpi, peaksid need paiknema enam-vähem sirgel joonel, mille kalle on litsentsi järgi ligikaudu −1.
- Katsed erinevate korpuste, keelereeglite ja morfoloogiliste normalisatsioonidega (lemmatiseerimine vs. vormide loendamine) aitavad mõista, kuidas andmetöötlus mõjutab tulemust.
Kokkuvõte: Zipfi seadus on lihtne, kuid võimas empiiriline tähelepanek, mis ilmneb keeles ja mitmesugustes sõnalistes ning sotsiaalsetes jaotustes. Kuigi selle täpne põhjus jääb osaliselt seletamata ja seadus ei kehti täpselt igas kontekstis, on see oluline tööriist, mis aitab kirjeldada ja modelleerida järjestatud sagedusi ning ärgitab otsima mehhanisme, mis toovad kaasa power-law käitumise.
Küsimused ja vastused
K: Mis on Zipfi seadus?
V: Zipfi seadus on empiiriline seadus, mis väidab, et sõna sagedus suures valimis on pöördvõrdeline selle järjekohaga sagedustabelis.
K: Kes pakkus välja Zipfi seaduse?
V: Zipfi seaduse pakkus esimesena välja keeleteadlane George Kingsley Zipf.
K: Kuidas seletab Zipfi seadus sõnade sagedust inglise keele sõnade valimis?
V: Zipfi seaduse kohaselt esineb kõige sagedasem sõna inglise keele sõnade valimis umbes kaks korda sagedamini kui teine sõna, kolm korda sagedamini kui kolmas sõna jne. See suundumus jätkub, kui sõna järjekoht väheneb.
Küsimus: Kui suure osa kõigist sõnadest moodustab kõige sagedamini esinev sõna ühes ingliskeelsete sõnade valimis?
V: Ühes inglise keele sõnade valimis moodustab kõige sagedamini esinev sõna ("the") peaaegu 7% kõigist sõnadest.
K: Milline on suhe poolte valimi moodustamiseks vajalike sõnade arvu ja nende sõnade sageduse vahel?
V: Zipfi seaduse kohaselt on vaja ainult umbes 135 sõna, et kajastada poole valimi sõnadest suures valimis.
K: Millised teised järjestused näitavad Zipfi seadust?
V: Sama seos, mida Zipfi seadus kirjeldab sõnade sageduse puhul, esineb ka muudes pingereas, mis ei ole seotud keelega, näiteks eri riikide linnade elanike, ettevõtete suuruse ja sissetulekute pingereas.
K: Kes on märganud jaotuse ilmnemist linnade edetabelites rahvaarvu järgi?
V: Jaotuse ilmumist linnade rahvastiku järgi koostatud edetabelites märkas esmakordselt Felix Auerbach 1913. aastal.
Seotud artiklid
Autor
AlegsaOnline.com Zipfi seadus — definitsioon, matemaatika ja näited keeles ja ühiskonnas Leandro Alegsa
URL: https://et.alegsaonline.com/art/110649
Allikad
- books.google.com : P. 139