Mikroarhitektuur: definitsioon, riistvara ja seos ISA-ga
Sügav ülevaade mikroarhitektuurist: definitsioon, riistvarakomponendid ja ISA-ga seotud seosed — selgitused, näited ja praktiline tähendus inseneridele ja üliõpilastele.
Arvutitehnikas on mikroarhitektuur (mõnikord lühendatult µarch või uarch) arvuti, keskseadme või digitaalse signaaliprotsessori elektrilise vooluahela kirjeldus, mis on piisav riistvara töö täielikuks kirjeldamiseks.
Teadlased kasutavad terminit "arvutikorraldus", samas kui arvutitööstuses töötavad inimesed ütlevad sagedamini "mikroarhitektuur". Mikroarhitektuur ja käsureaarhitektuur (ISA) moodustavad koos arvutiarhitektuuri valdkonna.
Pildigalerii
1 Pilt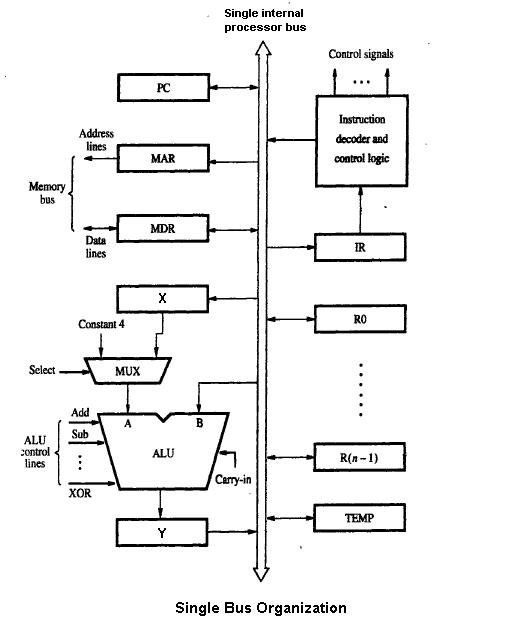
Mida mikroarhitektuur sisaldab?
Mikroarhitektuur määratleb detailid, kuidas ISA kaudu antud käsud tegelikult riistvaras realiseeritakse. See hõlmab:
- Andmekiired ja andmesiinid (registerfailid, registrid, andmeedastusrajad)
- Täitmeyjed ja ühikud (aritmeetika loogikaühikud — ALU, fpu, meediatöötlusüksused)
- Pipelining ehk torustused ja etappide jaotus, mis võimaldab käske samaaegselt töödelda)
- Joonehindamine (branch prediction) ja esitustusmeetodid, mis parandavad järjestuse efektiivsust)
- Vahemälud (caches) ning mälu hierarhia ja koherentsusmehhanismid
- Välised liidesed (bussid, I/O-sildid, mälukontrollerid)
- Kontrollilogika — kas kasutatakse mikrokoodi (microcode) või tahkest riistvarast juhitavat kontrollijada
- Energia- ja kella/tegeliku sageduse juhtimine (võimsusehaldus, taktsageduse dünaamika)
Kuidas mikroarhitektuur seostub ISA-ga?
Käsureaarhitektuur (ISA) määrab, millised käsud, registrid ja mälistruktuurid tarkvarale on nähtavad — see on liides operatsioonisüsteemi ja rakenduste jaoks. Mikroarhitektuur on see, kuidas see liides riistvaras tegelikult töötab. Sama ISA võib olla realiseeritud väga erinevate mikroarhitektuuridega: näiteks sama x86-ISA võib olla implementeeritud nii lihtsa, madala võimsusega protsessorina kui ka kõrge jõudlusega mitme tuumaga, väljaõppega protsessorina.
Tüüpilised disainitehnikad
- Pipelining — jagab käsutäitluse etappideks (nt laadimine, dekodeerimine, täitmine, salvestamine). See tõstab läbivoolu, kuid nõuab hargnemise ja sõltuvuste haldamist.
- Superscalar ja paralleelsus — mitu käsku täidetakse ühe tsükli jooksul paralleelselt.
- Väljastpoolt järjestuse täitmine (out-of-order execution) — parandab ressursikasutust, täites käske sõltumatult originaaljärjestusest, vajadusel ümberjärjestades tulemused õigeks.
- Registri ümbernimetamine — lahendab kirje-sõltuvusi ja võimaldab rohkem paralleelsust.
- Speculative execution ja branch prediction — vähendavad hargnemiste mõju, kuid vajavad mehhanisme eksituste tagajärgede tühistamiseks.
- Vahemälustrateegiad — mitmetasemelised cache’id (L1, L2, L3), assotsiatiivsuse valikud ja prefetching.
Riistvara realiseerimine ja tööriistad
Mikroarhitektuuri kavandatakse tavaliselt riistvarakirjelduskeeltega (näiteks Verilog või VHDL) ja seejärel sünteesitakse loogikaks, mis viiakse läbi kiibi tootmise protsessides. Disain hõlmab ka simuleerimist ja verifitseerimist (tõendamine, et disain vastab spetsifikatsioonile), milleks kasutatakse tarkvaralisi simulaatoreid ning formaalseid kontrollimeetodeid.
Microcode ja kontroll
Mõned protsessorid kasutavad mikrokoodi (väikest programmi riistvara sees), mis tõlgib kõrgema taseme ISA käsud madalamate kontrollisammudeni. See võimaldab lihtsamat vea parandamist ja keerukate ISA omaduste realiseerimist ilma täielikku riistvaralist ümberdisaini tegemata.
Disainikompromissid
Mikroarhitektuuri valikud mõjutavad kolme peamist mõõdet: jõudlus, võimsus ja pindala (area). Näiteks väljastpoolt järjestuse täitmine ja laiad superskalaarsed mootorid annavad head jõudlust, kuid tarbivad rohkem energiat ja võtavad rohkem kiipruumi. Taskesed või madala võimsusega seadmed eelistavad sageli lihtsamaid, energiasäästlikumaid mikroarhitektuure.
Mõju tarkvarale
Tarkvara (kompilaatorid, operatsioonisüsteemid) peab teadma ISA omadusi, kuid tihti optimeerivad kompilaatorid ja runtime-süsteemid koodi vastavalt konkreetsele mikroarhitektuurile (nt registreerimispaigutus, vahemälukäitumine, hargnemiste käitumine), et saavutada parem jõudlus.
Näited ja erinevused
- RISC vs CISC — RISC-architectuurid (nt mõned ARM-disainid) keskenduvad lihtsamatele, fikseeritud pikkusega käskudele, mida on lihtsam torustada ja optimeerida. CISC-architectureid (nt x86) pakuvad rikkalikumaid käsukomplekte; tänapäeval mapivad x86 protsessorid mitmekompleksse ISA lihtsamate sisekäskudeni, mille kaudu mikroarhitektuur neid täidab.
- Sarnane ISA, erinev mikroarhitektuur — sama ISA võib olla nii madala energia kui ka kõrge jõudlusega variantides, sõltuvalt torustuse, vahemälude, täitmismehhanismide ja taktisageduse valikutest.
Verifitseerimine ja turvalisus
Mikroarhitektuuril on suur mõju süsteemi turvalisusele — näiteks spekulatiivse täitmise ja vahemälu käitumise kõrvalproduktid võivad põhjustada küberturbe ründevektoreid (nt Spectre). Seetõttu on kaasaegsetes disainides järjest olulisem vormiline verifitseerimine, ründekindlate mehhanismide lisamine ja detailne testimine.
Kokkuvõte
Mikroarhitektuur on riistvara üksikasjalik kirjeldus, mis määrab, kuidas arvuti reaalselt ISA poolt ettenähtud käskusid täidab. See hõlmab paljusid tehnikaid ja kompromisse, mille eesmärk on optimeerida jõudlust, energiat ja kulu vastavalt sihtotstarbele — alates mikrokontrolleritest kuni tipptasemel serveri protsessoriteni.
Termini päritolu
Arvutid on kasutanud juhtimisloogika mikroprogrammeerimist alates 1950ndatest aastatest. Protsessor dekodeerib juhised ja saadab signaalid transistorlülitite abil sobivatele radadele. Mikroprogrammisõnade sees olevad bitid kontrollisid protsessorit elektriliste signaalide tasandil.
Vastupidiselt terminile: mikroarhitektuur kasutati mikroprogrammide poolt kontrollitud üksuste kirjeldamiseks: "arhitektuur", mis oli programmeerijatele nähtav ja dokumenteeritud. Kui arhitektuur pidi tavaliselt olema riistvarapõlvkondade vahel ühilduv, siis selle aluseks olevat mikroarhitektuuri võis kergesti muuta.
Seos käsurea arhitektuuriga
Mikroarhitektuur on seotud käsurea arhitektuuriga, kuid ei ole sama, mis käsurea arhitektuur. Käskude komplekti arhitektuur on lähedane protsessori programmeerimismudelile, nagu seda näeb assembleri programmeerija või kompilaatori kirjutaja, mis hõlmab täitmismudelit, protsessoriregistreid, mälu aadressirežiime, aadressi- ja andmeformaate jne. Mikroarhitektuur (või arvutikorraldus) on peamiselt madalama taseme struktuur ja seetõttu hallata suurt hulka üksikasju, mis on programmeerimismudelis varjatud. See kirjeldab protsessori sisemisi osi ja seda, kuidas need koos töötavad, et rakendada arhitektuurilist spetsifikatsiooni.
Mikroarhitektuurielementideks võivad olla kõik alates üksikutest loogikaväravatest kuni registrite, otsingutabeli, multiplekserite, loenduriteni jne, kuni täielike ALU-de, FPU-de ja isegi suuremate elementideni. Elektroonilise vooluahela tasandit võib omakorda jagada transistori tasandi üksikasjadeks, näiteks milliseid põhilisi väravaehitusstruktuure kasutatakse ja millised loogika rakendamise tüübid (staatiline/dünaamiline, faaside arv jne) on valitud, lisaks tegelikult kasutatud loogikadisainile, mis neid ehitas.
Mõned olulised punktid:
- Ühte mikroarhitektuuri, eriti kui see sisaldab mikrokoodi, saab kasutada mitmete erinevate käsukomplektide rakendamiseks, muutes selleks juhtimissalvestust. See võib aga olla üsna keeruline, isegi kui seda lihtsustatakse mikrokoodi ja/või tabelistruktuuride abil ROMides või PLA-des.
- Kahel masinal võib olla sama mikroarhitektuur ja seega sama plokkskeem, kuid täiesti erinev riistvara rakendamine. See hõlmab nii elektrooniliste lülituste kui ka veelgi enam füüsilise tootmise (nii integraallülituste ja/või diskreetsete komponentide) tasandit.
- Erineva mikroarhitektuuriga masinatel võib olla sama käsurea arhitektuur ja seega on mõlemad võimelised täitma samu programme. Uued mikroarhitektuurid ja/või vooluahela lahendused koos edusammudega pooljuhtide tootmises võimaldavad uuematel protsessoripõlvkondadel saavutada suuremat jõudlust.
Lihtsustatud kirjeldused
Väga lihtsustatud kõrgetasemeline kirjeldus - mis on turunduses tavaline - võib näidata ainult üsna põhilisi omadusi, nagu bussilaiused, koos erinevate täitmisüksuste tüüpidega ja muude suurte süsteemidega, nagu hargnemise ennustamine ja vahemälu, mis on kujutatud lihtsate plokkidena - võib-olla koos mõne olulise omaduse või tunnuse märkimisega. Mõnikord võidakse lisada ka mõningaid üksikasju torujuhtme struktuuri kohta (nagu otsimine, dekodeerimine, määramine, täitmine, tagasikirjutamine).
Mikroarhitektuuri aspektid
Pipelined datapath on tänapäeval mikroarhitektuuris kõige sagedamini kasutatav datapathi disain. Seda tehnikat kasutatakse enamikus kaasaegsetes mikroprotsessorites, mikrokontrollerites ja DSP-des. Pipelined arhitektuur võimaldab mitme käsu täitmist kattuvana, nagu koosteliinil. Torustik sisaldab mitmeid erinevaid etappe, mis on mikroarhitektuuride projekteerimisel väga olulised. Mõned neist etappidest hõlmavad käsu kättesaamist, käsu dekodeerimist, täitmist ja tagasikirjutamist. Mõned arhitektuurid sisaldavad ka muid etappe, näiteks mälule juurdepääsu. Pipeliinide projekteerimine on üks keskseid mikroarhitektuuriülesandeid.
Mikroarhitektuuri jaoks on olulised ka täitmisüksused. Täitmisüksuste hulka kuuluvad aritmeetilised loogikaüksused (ALU), ujukomaüksused (FPU), laadimis-/ladestusüksused ja hargnemiste ennustamine. Need üksused teostavad protsessori operatsioone või arvutusi. Täitmisüksuste arvu, nende latentsuse ja läbilaskevõime valik on olulised mikroarhitektuuri projekteerimise ülesanded. Mälude suurus, latentsus, läbilaskevõime ja ühendatavus süsteemis on samuti mikroarhitektuurilised otsused.
Süsteemi tasandi projekteerimisotsuseid, näiteks kas lisada välisseadmeid, näiteks mälukontrollerid, võib pidada mikroarhitektuuri projekteerimise osaks. See hõlmab ka otsuseid nende välisseadmete jõudlustaseme ja ühendatavuse kohta.
Erinevalt arhitektuuridisainist, mille peamine eesmärk on konkreetne jõudlustase, pööratakse mikroarhitektuuridisainis rohkem tähelepanu muudele piirangutele. Tähelepanu tuleb pöörata sellistele küsimustele nagu:
- Kiipide pindala/kulud.
- Energiatarve.
- Loogiline keerukus.
- Lihtne ühenduvus.
- Valmistatavus.
- Vigade kõrvaldamise lihtsus.
- Testitavus.
Mikroarhitektuuri kontseptsioonid
Üldiselt käivitavad kõik protsessorid, ühe kiibiga mikroprotsessorid või mitme kiibiga rakendused programme, sooritades järgmisi samme:
- Lugege juhendit ja dekodeerige see.
- Leidke kõik seotud andmed, mis on vajalikud käsu töötlemiseks.
- Töötle käsk.
- Kirjutage tulemused välja.
Seda lihtsa välimusega sammude seeriat raskendab asjaolu, et mäluhierarhia, mis hõlmab vahemälu, põhimälu ja mittepüsivaid mälusid, nagu kõvakettad, (kus on programmi käsud ja andmed) on alati olnud aeglasem kui protsessor ise. Samm (2) toob sageli kaasa viivituse (mida protsessori mõistes nimetatakse sageli "takistuseks"), kuni andmed jõuavad arvutibussi kaudu kohale. Palju on uuritud projekte, mis väldivad neid viivitusi nii palju kui võimalik. Aastate jooksul oli keskne projekteerimise eesmärk täita rohkem käske paralleelselt, suurendades seeläbi programmi tegelikku täitmiskiirust. Nende jõupingutuste käigus võeti kasutusele keerulised loogika- ja ahelastruktuurid. Varem sai selliseid tehnikaid rakendada ainult kallitel suurarvutitel või superarvutitel, kuna nende tehnikate jaoks oli vaja palju vooluahelaid. Pooljuhtide tootmise arenedes sai üha rohkem selliseid tehnikaid rakendada ühel pooljuhtkiibil.
Järgnevalt antakse ülevaade mikroarhitektuurilistest tehnikatest, mis on tänapäeva protsessorites levinud.
Käskude komplekti valik
Valik, millist käsureaarhitektuuri kasutada, mõjutab oluliselt suure jõudlusega seadmete rakendamise keerukust. Aastate jooksul andsid arvutite projekteerijad endast parima, et lihtsustada käsukomplekte, et võimaldada suurema jõudlusega rakendusi, säästes projekteerijate vaeva ja aega jõudlust parandavate funktsioonide jaoks, selle asemel et raisata neid käsukomplekti keerukusele.
Käskude komplekti disain on arenenud CISC, RISC, VLIW, EPIC tüüpi. Arhitektuurid, mis tegelevad andmete paralleelsusega, hõlmavad SIMD ja vektoreid.
Käskude pipelining
Üks esimesi ja kõige võimsamaid tehnikatest jõudluse parandamiseks on käsujuhtme kasutamine. Varajased protsessori disainilahendused viisid kõik eespool nimetatud sammud läbi ühe käsuga, enne kui läksid edasi järgmise käsu juurde. Suur osa protsessori vooluahelast jäeti iga sammu ajal kasutamata; näiteks käsu dekodeerimise vooluahel oli täitmisel kasutamata jne.
Pipeliinid parandavad jõudlust, võimaldades mitmel käsul korraga läbi protsessori töötada. Samas põhinäites hakkaks protsessor dekodeerima (samm 1) uut käsku, samal ajal kui viimane käsk ootab tulemusi. See võimaldaks korraga "lennata" kuni neli käsku, muutes protsessori neli korda kiiremaks. Kuigi iga üks käsk võtab sama kaua aega (endiselt on neli sammu), "loobub" protsessor tervikuna käskudest palju kiiremini ja saab töötada palju suurema taktimõõduga.
Cache
Kiipide tootmise täiustumine võimaldas paigutada samale kiibile rohkem vooluahelaid ja disainerid hakkasid otsima võimalusi nende kasutamiseks. Üks levinumaid viise oli kiibile üha suurema vahemälu lisamine. Vahemälu on väga kiire mälu, mälu, millele saab ligi mõne tsükliga, võrreldes sellega, mida on vaja põhimäluga suhtlemiseks. Protsessor sisaldab vahemälukontrollerit, mis automatiseerib vahemälu lugemise ja kirjutamise, kui andmed on juba vahemälus, siis need lihtsalt "ilmuvad", kui aga ei ole, siis protsessor "peatub", kuni vahemälukontroller need sisse loeb.
RISC-konstruktsioonides hakati vahemälu lisama 1980. aastate keskel ja lõpus, sageli ainult 4 KB ulatuses. See arv kasvas aja jooksul ja nüüd on tüüpilistel protsessoritel umbes 512 KB, samas kui võimsamatel protsessoritel on 1 või 2 või isegi 4, 6, 8 või 12 MB, mis on organiseeritud mitmetasandilise mäluhierarhia alusel. Üldiselt tähendab suurem vahemälu suuremat kiirust.
Käkid ja torujuhtmed sobisid ideaalselt kokku. Varem ei olnud palju mõtet ehitada torujuhtmeid, mis töötaksid kiiremini kui kiibivälise kassamälu ligipääsu latentsus. Kiibil oleva vahemälu kasutamine selle asemel tähendas, et torujuhtme sai töötada vahemälu juurdepääsu latentsuse kiirusega, mis on palju väiksem aeg. See võimaldas protsessorite töösagedusi suurendada palju kiiremini kui kiibivälise mälu puhul.
Haru prognoosimine ja spekulatiivne täitmine
Kaks peamist asja, mis takistavad suurema jõudluse saavutamist käsu tasandil paralleelsuse abil, on torujuhtme seisakud ja hargnemised. Alates ajast, mil protsessori käsu dekooder on avastanud, et ta on sattunud tingimusliku hargnemiskäsu peale, kuni ajani, mil saab välja lugeda otsustava hüpperegistri väärtuse, võib torujuhtme töö seiskuda mitu tsüklit. Keskmiselt on iga viies täidetav käsk hargnemine, seega on see suur aeglustumise hulk. Kui hargnemine toimub, on see veelgi hullem, sest siis tuleb kõik järgnevad käsud, mis olid torujuhtmes, kustutada.
Selliste hargnemiskaristuste vähendamiseks kasutatakse selliseid tehnikaid nagu hargnemiste ennustamine ja spekulatiivne täitmine. Hargnemiste ennustamine tähendab, et riistvara teeb haritud oletusi selle kohta, kas konkreetne hargnemine toimub. Arvatakse, et riistvara saab käsklusi ette tellida, ilma et ootaks registri lugemist. Spekulatiivne täitmine on täiendav täiustus, mille puhul täidetakse koodi mööda prognoositud teed enne, kui on teada, kas hargnemine peaks toimuma või mitte.
Järjekorras mittekohane täitmine
Vahemälu lisamine vähendab peamäluhierarhiast andmete kättesaamise ootamisest tulenevate seisakute sagedust või kestust, kuid ei kõrvalda neid seisakuid täielikult. Varasemate projektide puhul sundis vahemälu puudumine vahemälu kontrollerit protsessorit peatama ja ootama. Loomulikult võib programmis olla mõni teine käsk, mille andmed on sel hetkel vahemälus saadaval. Väljaspool järjekorda täitmine võimaldab seda valmis käsku töödelda, samal ajal kui vanem käsk ootab vahemälus, ning seejärel järjestab tulemused ümber, et näeks, et kõik toimus programmeeritud järjekorras.
Superskalaarne
Isegi kui eespool kirjeldatud kontseptsioonide toetamiseks oli vaja lisakomplekssust ja -väravaid, võimaldas pooljuhtide tootmise täiustamine peagi kasutada veelgi rohkem loogikaväravaid.
Ülaltoodud visandis töötleb protsessor ühe käsu osa korraga. Arvutiprogramme saaks kiiremini täita, kui mitut käsku korraga töödelda. Seda saavutavadki superskalaarsed protsessorid, kordistades funktsionaalseid üksusi, näiteks ALUsid. Funktsionaalsete üksuste paljundamine sai võimalikuks alles siis, kui integreeritud vooluahela (mida mõnikord nimetatakse ka "die") pindala ei ületanud enam usaldusväärselt valmistatava protsessori piire. 1980ndate lõpus hakkasid turule jõudma superskalaarsed protsessorid.
Kaasaegsetes disainilahendustes on tavaline, et leidub kaks laadimisüksust, üks salvestusüksus (paljudel käskudel ei ole salvestatavaid tulemusi), kaks või enam täisarvu matemaatikaseadet, kaks või enam ujukomaüksust ja sageli ka mingi SIMD-üksus. Käskude väljastamise loogika muutub üha keerulisemaks, lugedes mälust sisse tohutu hulga käskude nimekirja ja andes need edasi erinevatele täitmisüksustele, mis on sel hetkel kasutuseta. Seejärel kogutakse tulemused kokku ja järjestatakse lõpus uuesti.
Registri ümbernimetamine
Registrite ümbernimetamine viitab tehnikale, mida kasutatakse selleks, et vältida programmi käskude mittevajalikku järjestikust täitmist, kuna need käsud kasutavad samu registreid uuesti. Oletame, et meil on kaks gruppi juhiseid, mis kasutavad sama registrit, üks käsukomplekt täidetakse esimesena, et jätta register teisele komplektile, kuid kui teine komplekt on määratud teisele sarnasele registrile, saab mõlemat käsukomplekti paralleelselt täita.
Mitmeprotsessorlus ja mitmikprotsessorlus
Kuna protsessori töösageduse ja DRAMi ligipääsuaegade vahel on üha suurem vahe, ei suutnud ükski tehnikatest, mis suurendavad käsu-tasandi paralleelsust (ILP) ühe programmi sees, ületada pikki seisakuid (viivitusi), mis tekkisid siis, kui andmeid tuli põhimälust välja võtta. Lisaks sellele nõudsid täiustatud ILP-tehnika jaoks vajalikud suured transistorite arvud ja kõrged töösagedused energiatarbimise taset, mida ei saanud enam odavalt jahutada. Nendel põhjustel on uuemate põlvkondade arvutid hakanud kasutama kõrgemaid paralleelsuse tasemeid, mis eksisteerivad väljaspool ühte programmi või programmiliini.
Seda suundumust nimetatakse mõnikord "läbilaskevõimeliseks arvutuseks". See idee sai alguse suurarvutite turult, kus veebipõhine tehingutöötlus ei rõhutanud mitte ainult ühe tehingu täitmise kiirust, vaid võimet käsitleda suurt hulka tehinguid korraga. Kuna tehingupõhised rakendused, nagu võrgu marsruutimine ja veebisaitide teenindamine, on viimasel kümnendil oluliselt kasvanud, on arvutitööstus taas rõhutanud läbilaskevõime ja läbilaskevõime küsimusi.
Üks meetod, kuidas seda paralleelsust saavutada, on mitme protsessoriga arvutisüsteemid. Varem oli see reserveeritud kõrgekvaliteediliste suurarvutite jaoks, kuid nüüd on väikeettevõtete turul levinud väikesemahulised (2-8) mitme protsessoriga serverid. Suurettevõtete jaoks on levinud suuremahulised (16-256) multiprotsessorid. Alates 1990ndatest aastatest on ilmunud isegi mitme protsessoriga personaalarvutid.
Edusammud pooljuhttehnoloogias vähendasid transistori suurust; on ilmunud mitmetuumalised protsessorid, kus mitu protsessorit on rakendatud samal ränikiibil. Esialgu kasutati neid kiipides, mis olid suunatud manussüsteemide turgudele, kus lihtsamad ja väiksemad protsessorid võimaldasid mitme instantsi mahutamist ühele ränitükile. Aastaks 2005 võimaldas pooljuhttehnoloogia toota suures mahus kahte tipptasemel lauaarvutite CMP-kiipi. Mõnes konstruktsioonis, näiteks UltraSPARC T1, kasutati lihtsamaid (skalaarseid, järjestatud) konstruktsioone, et ühele ränitükile mahuks rohkem protsessoreid.
Viimasel ajal on populaarsemaks muutunud veel üks tehnika, milleks on multitöötlus. Mitmesideseeria puhul, kui protsessor peab aeglasest süsteemimälust andmeid hankima, siis selle asemel, et oodata andmete saabumist, lülitub protsessor teise programmi või programmiliini, mis on valmis täitma. Kuigi see ei kiirenda konkreetset programmi/niiti, suurendab see süsteemi üldist läbilaskevõimet, vähendades protsessori tühikäigu aega.
Kontseptuaalselt on multithreading samaväärne kontekstivahetusega operatsioonisüsteemi tasandil. Erinevus seisneb selles, et mitmikeeruline protsessor saab teha niidivahetuse ühe protsessoritsükliga, mitte sadade või tuhandete protsessoritsüklitega, mida kontekstivahetuse tegemine tavaliselt nõuab. See saavutatakse riistvara (näiteks registrifaili ja programmiloenduri) kordamise teel iga aktiivse niidi jaoks.
Täiendav täiustus on samaaegne mitmikeeramine. See tehnika võimaldab superskalaarsetel protsessoritel üheaegselt ja samas tsüklis täita erinevate programmide/niitide käske.
Seotud leheküljed
- Mikroprotsessor
- Mikrokontroller
- Mitmetuumaline protsessor
- Digitaalne signaaliprotsessor
- Protsessori disain
- Datapath
- käsutustasandi paralleelsus (ILP)
Küsimused ja vastused
K: Mis on mikroarhitektuur?
V: Mikroarhitektuur on arvuti, keskseadme või digitaalse signaaliprotsessori elektriskeemi kirjeldus, mis on piisav riistvara töö täielikuks kirjeldamiseks.
K: Kuidas viitavad teadlased sellele mõistele?
V: Teadlased kasutavad mikroarhitektuurile viidates mõistet "arvutiorganisatsioon".
K: Kuidas viitavad inimesed arvutitööstuses sellele mõistele?
V: Inimesed arvutitööstuses ütlevad sellele mõistele viidates sagedamini "mikroarhitektuur".
K: Millised kaks valdkonda moodustavad arvutiarhitektuuri?
V: Mikroarhitektuur ja käsureaarhitektuur (ISA) moodustavad koos arvutiarhitektuuri valdkonna.
K: Mida tähendab ISA?
V: ISA tähendab käsureaarhitektuuri.
K: Mida tähendab µarch? V: µArch tähendab mikroarhitektuuri.
Seotud artiklid
Autor
AlegsaOnline.com Mikroarhitektuur: definitsioon, riistvara ja seos ISA-ga Leandro Alegsa
URL: https://et.alegsaonline.com/art/64586
Allikad
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture